Loading packages and exploring data
This course focuses on using the tidyverse; a free collection of programming packages that will allow you to write code that imports data, tidys it, transforms it into useful datasets, visualises findings, creates statistical models and communicates findings to others data using a standardised set of commands.
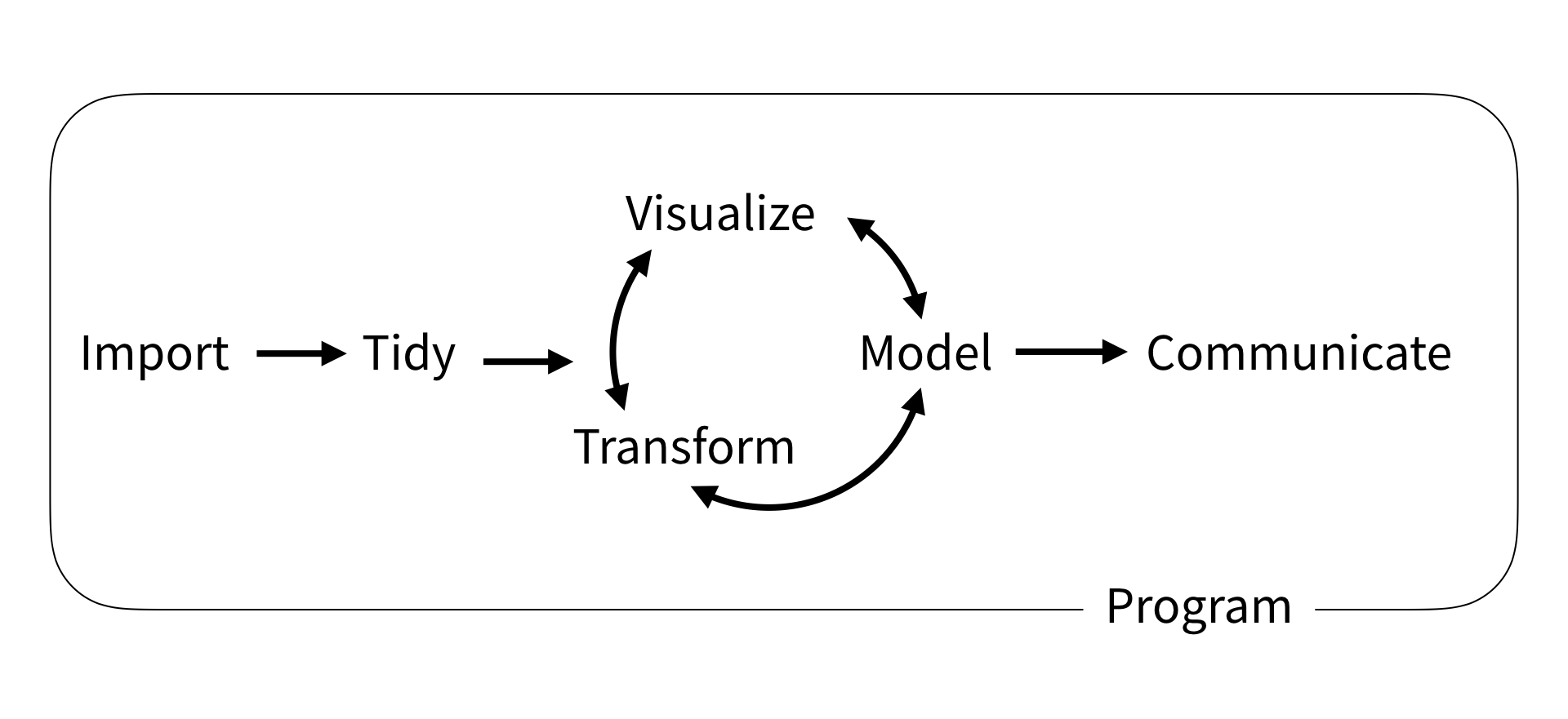
For many people the tidyverse is the main reason that they use R. The tidyverse is used widely in government, academia, NGOs and industry, notable examples include the Financial Times and the BBC. Code in the tidyverse can be (relatively) easily understood by others and you, when you come back to a project after several months.
Try this out
The code above transforms data and converts it into a graph. It doesn’t have any comments, but you should hopefully be able to understand what a lot of the code does by just reading it. Can you guess what each line does? Try running the code by selecting parts of it and pressing control | command ⌘ and Enter
1 Loading data
We can’t do much with R without loading data from elsewhere. Data will come in many formats and R should be able to deal with all of them. Some of the datasets you access will be a few rows and columns; others, like the ones we are going to use on this course, might run into hundreds of thousands or even millions of rows and hundreds or thousands of columns. Depending on the format you are using, you might need to use specific packages. A few of the data file types you might meet are described below:
| File type | Description |
|---|---|
| Comma separated values [.csv] | As it says in the name, .csv files store data by separating data items with commas. They are a common way of transferring data and can be easily created and read by Excel, Google spreadsheets and text editors (in addition to R). CSVs aren’t compressed so will generally be larger than other file types. They don’t store information on the types of data stored in the file so you might find yourself having to specify that a date column is a date, rather than a string of text. You can read and write csv files without the need to load any packages, but if you do use readr you might find things go much faster. |
| Excel [.xls | .xlsx | .xlsxm] | Excel files store data in a compressed custom format. This means files will generally be smaller than CSVs and will also contain information on the types of data stored in different columns. R can read and write these files using the openxlsx package, but you can also use the tidyverse’s readxl for reading, and writexl for writing for excel formats. |
| R Data [.rds] | R has it’s own data format, .rds. Saving to this format means that you will make perfect copies of your R data, including data types and factors. When you load .rds files they will look exactly the same as when you saved them. Data can be highly compressed and it’s one of the fastest formats for getting data into R. You can read and write .rds files without the need to load any packages, but using the functions in readr might speed things up a bit. You won’t be able to look at .rds files in other programs such as Excel |
| Arrow [.parquet] | Apache Arrow .parquet is a relatively new format that allows for the transfer of files between different systems. Files are small and incredibly fast to load, whilst looking exactly the same as when you save them. The PISA dataset used here, that takes ~20 seconds to load in .rds format, will load in less than 2 seconds in .parquet format. Because of the way that data is stored you won’t be able to open these files in programs such as Excel. You will need the arrow package to read and write .parquet files. |
| SPSS [.sav] | SPSS is a common analysis tool in the world of social science. The native format for SPSS data is .sav. These files are compressed and include information on column labels and column datatypes. You will need either the haven or foreign packages to read data into R. Once you have loaded the .sav you will probably want to convert the data into a format that is more suitable for R, normally this will involve converting columns into factors. We cover factors in more detail below. |
| Stata [.dta] |
haven or foreign packages to read data into R |
| SAS [.sas] |
haven or foreign packages to read data into R |
| Structured Query Language [.sql] | a common format for data stored in large databases. Normally SQL code would be used to query these, you can use the tidyverse to help construct SQL this through the package dbplyr which will convert your tidyverse pipe code into SQL. R can be set up to communicate directly with databases using the DBI package. |
| JavaScript Object Notation [.json] |
.json is a popular format for sharing data on the web. You can use jsonlite and rjson to access this type of data |
For this course we will be looking at .csv, excel, .rds and parquet files.
2 Dataframes
Loading datasets into R will normally store them as dataframes (also known as tibbles when using the tidyverse). Dataframes are the equivalent of tables in a spreadsheet, with rows, columns and datatypes.
The table above has 4 columns, each column has a datatype, CNT is a character vector, PV1MATH is a double (numeric) vector, ESCS is a double (numeric) vector and ST211Q01HA is a factor. For more about datatypes, see ?@sec-datatypes
Core to the tidyverse is the idea of tidy data, a rule of thumb for creating data sets that can be easily manipulated, modeled and presented. Tidy data are data sets where each variable is a column and each observation a row.
This data isn’t tidy data as each row has contains multiple exam results (observations):
| ID | Exam 1 | Grade 1 | Exam 2 | Grade 2 |
|---|---|---|---|---|
| R2341 | English | 4 | Maths | 5 |
| R8842 | English | 5 |
This dataframe is tidy data as each student has one entry for each exam:
| ID | Exam | Grade |
|---|---|---|
| R2341 | English | 4 |
| R2341 | Maths | 5 |
| R8842 | English | 5 |
First we need to get some data into R so we can start analysing them. We can load large datatables into R by either providing the online web address, or by loading it from a local file directory on your hard drive. Both methods are covered below:
3 Loading data from the web
To download files from the web you’ll need to find the exact location of the file you are using. For example below we will need another package, openxlsx, which you need to install before you load it (see: ?@sec-packages, or use line 1 below). The code shown will download the files from an online Google drive directly into objects in R using read.xlsx(<file_web_address>, <sheet_name>):
To convert data on your google drive into a link that works in R, you can use the following website: https://sites.google.com/site/gdocs2direct/. Note that not all read/load commands in R will work with web addresses and some will require you have to copies of the datasets on your disk drive. Additionally, downloading large datasets from the web directly into R can be very slow, loading the dataset from your harddrive will nearly always be much faster.
4 Loading data from your computer
Downloading files directly from web addresses can be slow and you might want to prefer to use files saved to your computer’s hard drive. You can do this by following the steps below:
Download the PISA_2018_student_subset.parquet file from here and save it to your computer where your R code file is.
Copy the location of the file (see next step for help)
-
To find the location of a file in Windows do the following:
-
Navigate to the location of the file in Windows Explorer:

-
Click on the address bar
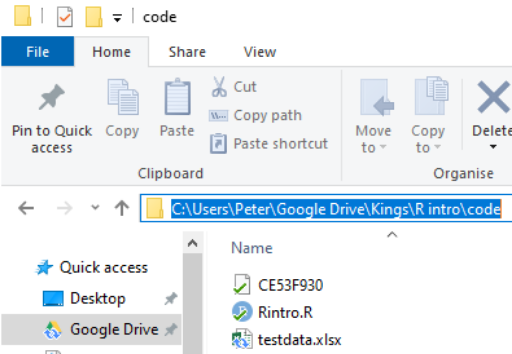
Copy the location
-
-
To find the location of a file in Mac OSX do the following:
Open Finder
Navigate to the folder where you saved the file
-
Right click on the name of the file, then press the option
⌥(orAlt) button and selectCopy <name of file> as Pathname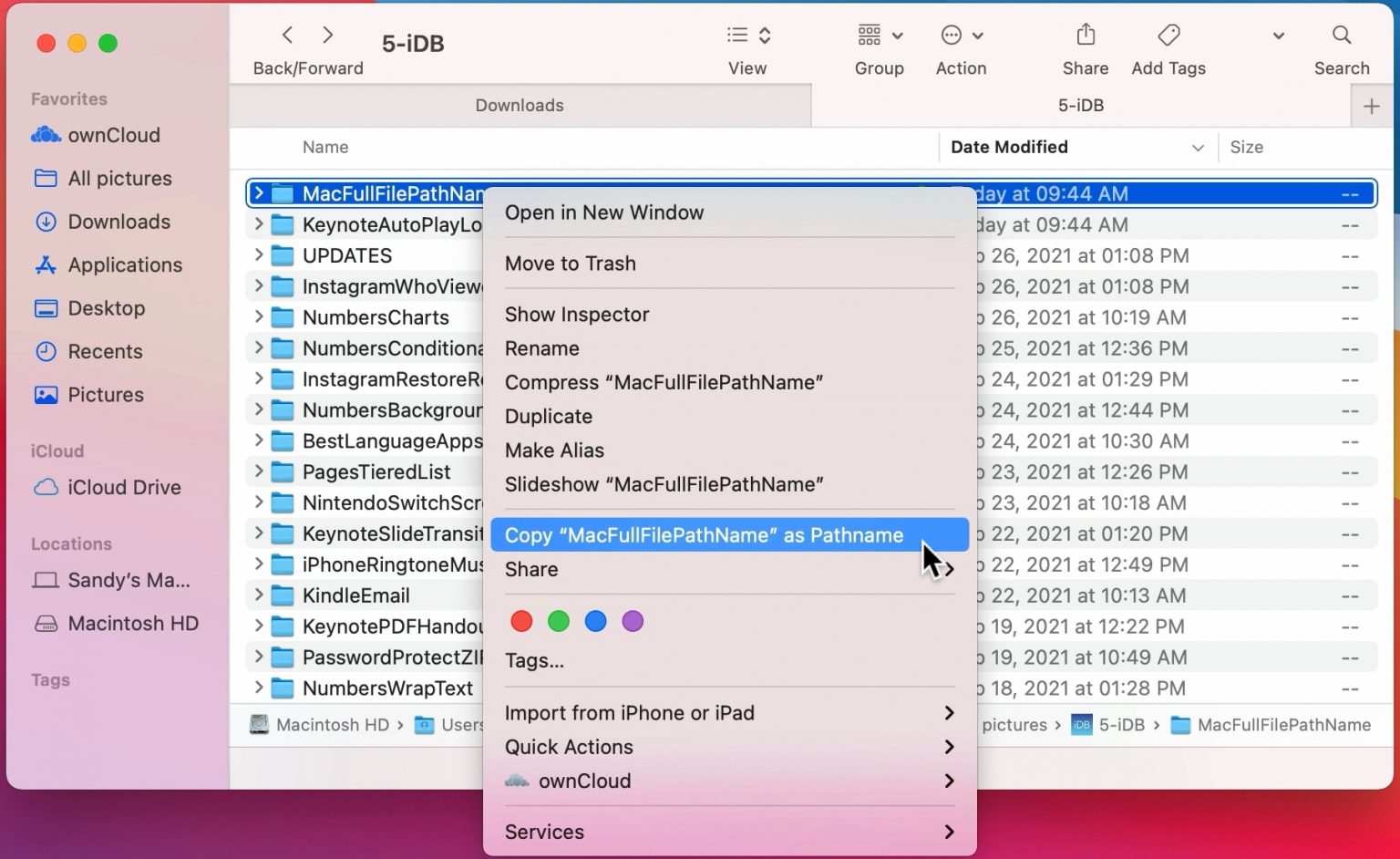
Alternatively, follow this
To load this particular data into R we need to use the read_parquet command from the arrow package, specifying the location and name of the file we are loading. See the following code:
5 Setting working directories
Using the setwd(<location>) you can specify where R will look by default for any datasets. In the example below, the dfe_data.xlsx will have been downloaded and stored in C:/Users/Peter/code. By running setwd("C:/Users/Peter/code") R will always look in that location when trying to load files, meaning that read_parquet(r"[C:/Users/Peter/code/PISA_2018_student_subset.parquet]") will be treated the same as read_parquet(r"[PISA_2018_student_subset.parquet]")
To work out what your current working directory is, you can use getwd().
5.1 Proper addresses
You might have found that you get an error if you don’t convert your backslashes \ into forwardslashes /. It’s common mistake and very annoying. In most programming languages a backslash signifies the start of a special command, for example \n signifies a newline.
With R there are three ways to get around the problem of backslashes in file locations, for the location:"C:\myfolder\" we could:
- replace them with forwardslashes (as shown above):
"C:/myfolder/" - replace them with double backslashes (the special character specified by two backslashes is one backslash!):
"C:\\myfolder\\" - use the inbuilt R command to deal with filenames:
r"[C:\myfolder\]"
6 .parquet files
For the majority of this workbook you will be using a cutdown version of the PISA_2018 student table. This dataset is huge and we have loaded it into R, selected fields we think are useful, converted column types to work with R and saved in the .parquet format. .parquet files are quick to load and small in size. To load a .parquet file you can use the read_parquet(<location>) command from the arrow package.
If you want to save out any of your findings, you can use write_parquet(<object>, <location>), where object is the table you are working on and location is where you want to save it.
7 .csv files
A very common way of distributing data is through .csv files. These files can be easily compressed and opened in common office spreadsheet tools such as Excel. To load a .csv we can use read_csv("<file_location>")
You might want to save your own work as a .csv for use later or for manipulation in another tool e.g. Excel. To do this we can use write_csv(<your_data>, "<your_folder><name>.csv"). NOTE: don’t forget to add .csv to the end of your “
8 Exploring data
Now that we have loaded the PISA_2018 dataset we can start to explore it.
You can check that the tables have loaded correctly by typing the object name and ‘running’ the line (control|command ⌘ and Enter)
# A tibble: 612,004 × 205
CNT OECD ISCEDL ISCEDD ISCEDO PROGN WVARSTRR COBN_F COBN_M COBN_S GRADE
* <fct> <fct> <fct> <fct> <fct> <fct> <dbl> <fct> <fct> <fct> <fct>
1 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
2 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
3 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
4 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
5 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
6 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
7 Albania No ISCED … C Vocat… Alba… 3 Missi… Missi… Missi… 0
8 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
9 Albania No ISCED … C Vocat… Alba… 3 Alban… Alban… Alban… 0
10 Albania No ISCED … C Vocat… Alba… 3 Missi… Missi… Missi… 0
# ℹ 611,994 more rows
# ℹ 194 more variables: SUBNATIO <fct>, STRATUM <fct>, ESCS <dbl>, LANGN <fct>,
# LMINS <dbl>, OCOD1 <fct>, OCOD2 <fct>, REPEAT <fct>, CNTRYID <fct>,
# CNTSCHID <dbl>, CNTSTUID <dbl>, NatCen <fct>, ADMINMODE <fct>,
# LANGTEST_QQQ <fct>, LANGTEST_COG <fct>, BOOKID <fct>, ST001D01T <fct>,
# ST003D02T <fct>, ST003D03T <fct>, ST004D01T <fct>, ST005Q01TA <fct>,
# ST007Q01TA <fct>, ST011Q01TA <fct>, ST011Q02TA <fct>, ST011Q03TA <fct>, …We can see from this that the tibble (another word for dataframe, basically a spreadsheet table) is 612004 rows, with 205 columns 1. This is data for all the students from around the world that took part in PISA 2018. The actual PISA dataset has many more columns than this, but for the examples here we have selected 205 of the more interesting data variables. The column names might seem rather confusing and you might want to refer to the PISA 2018 code book to find out what everything means.
The data shown in the console window is only the top few rows and first few columns. To see the whole table click on the Environment panel and the table icon ![]() to explore the table:
to explore the table:

Alternatively, you can also hold down command ⌘|control and click on the table name in your R Script to view the table. You can also type View(<table_name>). Note: this has a capital “V”
In the table view mode you can read the label attached to each column, this will give you more detail about what the column stores. If you hover over columns it will display the label:

Alternatively, to read the full label of a column, the following code can be used:
[1] "How many books are there in your home?"Each view only shows you 50 columns, to see more use the navigation panel:

To learn more about loading data from in other formats, e.g. SPSS and STATA, look at the tidyverse documentation for haven.
The PISA_2018 dataframe is made up of multiple columns, with each column acting like a vector, which means each column stores values of only one datatype. If we look at the first four columns of the schools table, you can see the CNTSTUID, ESCS and PV1MATH columns are <dbl> (numeric) and the other three columns are of <fctr> (factor), a special datatype in R that helps store categorical and ordinal variables, see ?@sec-factors for more information on how factors work.
# A tibble: 5 × 5
CNTSTUID ST004D01T CNT ESCS PV1MATH
<dbl> <fct> <fct> <dbl> <dbl>
1 800251 Male Albania 0.675 490.
2 800402 Male Albania -0.757 462.
3 801902 Female Albania -2.51 407.
4 803546 Male Albania -3.18 483.
5 804776 Male Albania -1.76 460.Vectors are data structures that bring together one or more data elements of the same datatype. E.g. we might have a numeric vector recording the grades of a class, or a character vector storing the gender of a set of students. To define a vector we use c(item, item, ...), where c stands for combine. Vectors are very important to R, even declaring a single object, x <- 6, is creating a vector of size one. To find out more about vectors see: ?@sec-vectors
We can find out some general information about the table we have loaded. nrow and ncol tell you about the dimensions of the table
[1] 612004[1] 205If we want to know the names of the columns we can use the names() command that returns a vector. This can be a little confusing as it’ll return the names used in the dataframe, which can be hard to interpret, e.g. ST004D01T is PISA’s way of encoding gender. You might find the labels in the view of the table available through view(PISA_2018) and the Environment panel easier to navigate:
[1] "CNT" "OECD" "ISCEDL" "ISCEDD" "ISCEDO" "PROGN"
[7] "WVARSTRR" "COBN_F" "COBN_M" "COBN_S" "GRADE" "SUBNATIO"
[13] "STRATUM" "ESCS" "LANGN"
[ reached getOption("max.print") -- omitted 190 entries ]As mentioned, the columns in the tables are very much like a collection of vectors, to access these columns we can put a $ [dollar sign] after the name of a table. This allows us to see all the columns that table has, using the up and down arrows to select, press the Tab key to complete:

[1] Male Male Female Male Male Female Female Male Female Female
[11] Female Female Female Female Male
[ reached getOption("max.print") -- omitted 611989 entries ]
attr(,"label")
[1] Student (Standardized) Gender
Levels: Female Male Valid Skip Not Applicable Invalid No ResponseWe can apply functions to the returned column/vector, for example: sum, mean, median, max, min, sd, round, unique, summary, length. To find all the different/unique values contained in a column we can write:
[1] Albania United Arab Emirates Argentina
[4] Australia Austria Belgium
[7] Bulgaria Bosnia and Herzegovina Belarus
[10] Brazil Brunei Darussalam Canada
[13] Switzerland Chile Colombia
[ reached getOption("max.print") -- omitted 65 entries ]
82 Levels: Albania United Arab Emirates Argentina Australia Austria ... VietnamWe can also combine commands, with length(<vector>) telling you how many items are in the unique(PISA_2018$CNT) command
You might meet errors when you try and run some of the commands because a field has missing data, recorded as NA. In the case below it doesn’t know what to do with the NA values in PV1MATH, so it gives up and returns NA:
You can see the NAs by just loking at this column:
[1] 0.6747 -0.7566 -2.5112 -3.1843 -1.7557 -1.4855 NA -3.2481 -1.7174
[10] NA -1.5617 -1.9952 -1.6790 -1.1337 NA
[ reached getOption("max.print") -- omitted 611989 entries ]
attr(,"label")
[1] "Index of economic, social and cultural status"To get around this you can tell R to remove/ignore the NA values when performing maths calculations:
R’s inbuilt mode function doesn’t calculate the mathematical mode, instead it tells you what type of data you are dealing with. You can work out the mode of data by using the modeest package:
There is more discussion on how to use modes in R here
Calculations might also be upset when you try to perform maths on a column that is stored as another datatype. For example if you wanted to work out the mean common number of minutes spent learning the language that the PISA test was sat in, e.g. number of hours of weekly English lessons in England:
Looking at the structure of this column, we can see it is stored as a factor, not as a numeric
num [1:612004] 90 180 90 90 400 150 NA NA 180 NA ...
- attr(*, "label")= chr "Learning time (minutes per week) - <test language>"So we need to change the type of the column to make it work with the mean command, changing it to as.numeric(<column>) for the calculation, for more details on datatypes, see ?@sec-datatypes.
# this isn't ideal for proper analysis as you will need to remove all the "No Response" data
mean(as.numeric(PISA_2018$LMINS), na.rm = TRUE)[1] 223.747To get a good overview of what a table contains, you can use the str(<table_name>) and summary(<table_name>) commands.
8.1 Questions
Using the PISA_2018 dataset:
- use the Environment window to view the dataset, what is the name and the label of the 100th column?
answer
# the 100th column is ST102Q02TA
# the label is: "How often during <test language lessons>: The teacher asks questions to check whether we have understood what was taught"
# you could use View() instead of the environment window, note the capital V
View(PISA_2018)
# use could use the vector subset to fetch the 100th name
names(PISA_2018)[100]
# you could use the attr function to find the label
attr(PISA_2018$ST102Q02TA, "label")
# or using the dollar sign to load this field will also give the label
PISA_2018$ST102Q02TA- Use the dollar sign
$to return the columnST004D01T. What is stored in this column?
answer
# Student (Standardized) Gender
PISA_2018$ST004D01T
# [1] Male Male Female Male Male Female Female Male Female Female
# [11] Female Female Female Female Male Female Male Male Male Male
# [21] Male Male Female Male Male Female Male Female Male Male
# [31] Female Female Female Female Female Male Male Male Male Female
# [ reached getOption("max.print") -- omitted 611964 entries ]
# attr(,"label")
# [1] Student (Standardized) Gender
# Levels: Female Male Valid Skip Not Applicable Invalid No Response- How many students results are in the whole table?
- What
uniquevalues does the dataset hold for Mother’s occupationOCOD1and Father’s occupationOCOD2? Which is larger?
- What are the
maximum,mean,medianandminumum science gradesPV1SCIEachieved by any student
- Explore the dataset and makes notes about the range of values of 2 other columns
Footnotes
Even in this cut down format the PISA data might take a few minutes to load. You can find the full dataset here, but be warned, it might crash you machine when trying to load it! Plug your laptop into a power supply, and having 16GB of RAM highly recommended! You might also need to wrangle some of the fields to make them work for your purposes, you might enjoy the challenge!↩︎